
ใน Product Innovation Keynote วันนี้ Google ได้เปิดตัวเทคโนโลยีและบริการใหม่ๆ ที่เกี่ยวกับข้อมูลออกมาเป็นจำนวนมาก โดยเฉพาะในเรื่องของ Smart Analytics ในบทความนี้ เดี๋ยวจะมาเล่าให้ฟังในส่วนของเทคโนโลยีที่เกี่ยวข้องกับการสร้างโมเดล Machine Learning ให้ฟังกันก่อน
ปีนี้ Google ยังคงโฟกัสในเรื่องของการทำให้ทุกคนในองค์กรสามารถใช้ประโยชน์จาก AI/Machine Learning ได้มากขึ้น และสามารถเริ่มต้นสร้างโมเดลได้เองแบบง่ายๆ
1. BigQuery ML
ปีที่แล้ว Google เปิดตัวฟีเจอร์ใหม่ BigQuery ML ที่มาช่วยให้ Data Scientist/Analyst สามารถสร้างโมเดล Machine Learning บนข้อมูลขนาดใหญ่ใน Google BigQuery ได้ง่าย ๆ ผ่าน SQL query ใครที่ยังไม่เคยได้ยิน ตามไปอ่านบทความด้านล่างนี้จากปีที่แล้วกันก่อน
BigQuery ML เป็นหนึ่งในเทคโนโลยีที่ถูกหยิบยกขึ้นมาเป็นกรณีศึกษาเยอะมากตลอดงาน Cloud Next ในปีนี้ โดยในงาน Google ได้เปิดตัวโมเดลเพิ่มเติมอีก 3 อัน คือ
- K-means clustering สำหรับการจัดกลุ่มข้อมูล และ
- Matrix factorization สำหรับการแนะนำสินค้าและบริการ (recommendation)
- Tensorflow Deep Neural Network สำหรับนำโมเดล Tensorflow ที่มีอยู่แล้วมาใช้ใน BigQuery ML
เนื่องจากสองตัวหลังยังอยู่ใน Alpha วันนี้เลยจะมาลองเล่น K-means ให้ดูอย่างเดียวก่อนโดยใช้ข้อมูล Facebook โพสต์จากเพจ Skooldio เช่นเดียวกับตัวอย่างจากบทความในปีที่แล้ว
Create
การสร้างโมเดลก็ง่ายเหมือนเดิม แค่เปลี่ยนประเภทโมเดลเป็น kmeans และกำหนดวิธีการคำนวณระยะทางระหว่างข้อมูลสองจุด distance_type ว่าจะใช้เป็น EUCLIDEAN หรือ COSINE
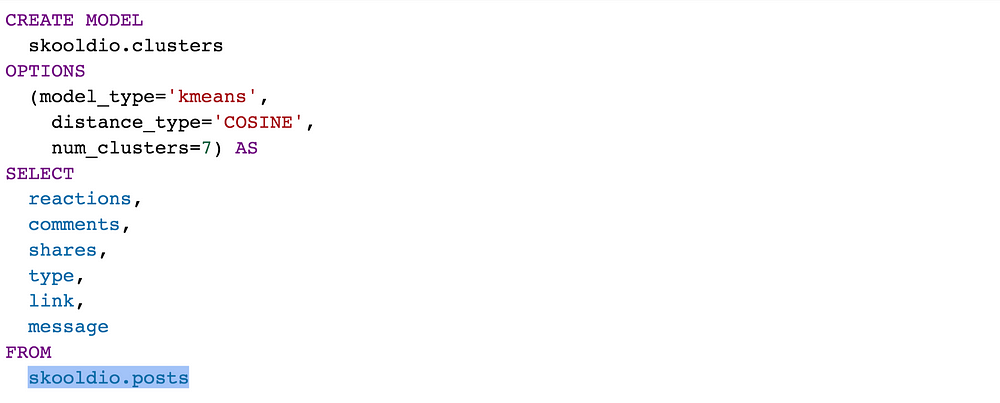
Evaluate
พอสร้างโมเดลเสร็จ ก็จะได้ผลหน้าตาประมาณนี้ออกมา รายละเอียดของทั้งสอง metrics นี้ขอไม่พูดถึง เดี๋ยวจะยาว

หรือถ้าใครอยากเรียกดูผลด้วยคำสั่ง SQL ก็สามารถทำได้เช่นกัน
SELECT * FROM ML.EVALUATE(MODEL skooldio.clusters)
Predict
อยากจะดูผล ก็ใช้คำสั่ง ML.PREDICT ได้เลย

โดยผลที่ได้ ก็จะแจกแจงให้ว่าแต่ละจุดข้อมูลถูกจัดลง cluster ไหน และระยะทางจุดข้อมูลไปยัง centroids ของ cluster ที่อยู่ใกล้ที่สุด 5 clusters เป็นเท่าไหร่บ้าง

จากตัวอย่างข้างต้น ข้อมูลแถวที่ 2 ถูกจัดอยู่ใน Cluster 6 โดยระยะทางจากข้อมูลไปยัง centroid ของ cluster อยู่ที่ 0.54
2. AutoML Tables
ปีที่แล้ว Google ได้เปิดตัว Cloud AutoML เทคโนโลยีในการสร้างโมเดล Machine Learning อัตโนมัติ โดยใช้เทคนิคขั้นสูงอย่าง learning2learn และ transfer learning เพื่อช่วยให้ทุกคนสามารถสร้างโมเดล AI ที่มีคุณภาพดีได้
ในปีนี้ Google ได้เปิดตัว AutoML Tables ซึ่งเป็นการต่อยอดนำ AutoML มาใช้กับข้อมูลแบบ Structured (ตารางข้อมูลที่พวกเราคุ้นเคยกันดีนี่แหละ) เพื่อช่วยสร้างโมเดลที่มีประสิทธิภาพจากตารางข้อมูลปริมาณมากๆ ได้อย่างรวดเร็ว
มาลองดูกันหน่อยสิว่ามันทำงานยังไง? ข้อมูลที่ใช้เป็นข้อมูล Facebook โพสต์จากเพจอีเจี๊ยบเลียบด่วน กับ Drama Addict โดยเราจะมาสร้างโมเดลเพื่อทำนายว่าโพสต์ไหน มาจากเพจอะไร
Import
เริ่มต้นจากการโหลดข้อมูลเข้าไปก่อน โดยจะโหลดจาก Table ใน BigQuery หรือโหลดไฟล์ CSV จาก Cloud Storage ก็ได้ ข้อมูลที่โหลดเข้าไปจะต้องมีอย่างน้อย 1,000 แถว และ 2 คอลัมน์ (คือต้องมี target ที่จะทำนาย กับ feature อีกอย่างน้อยหนึ่งตัว)
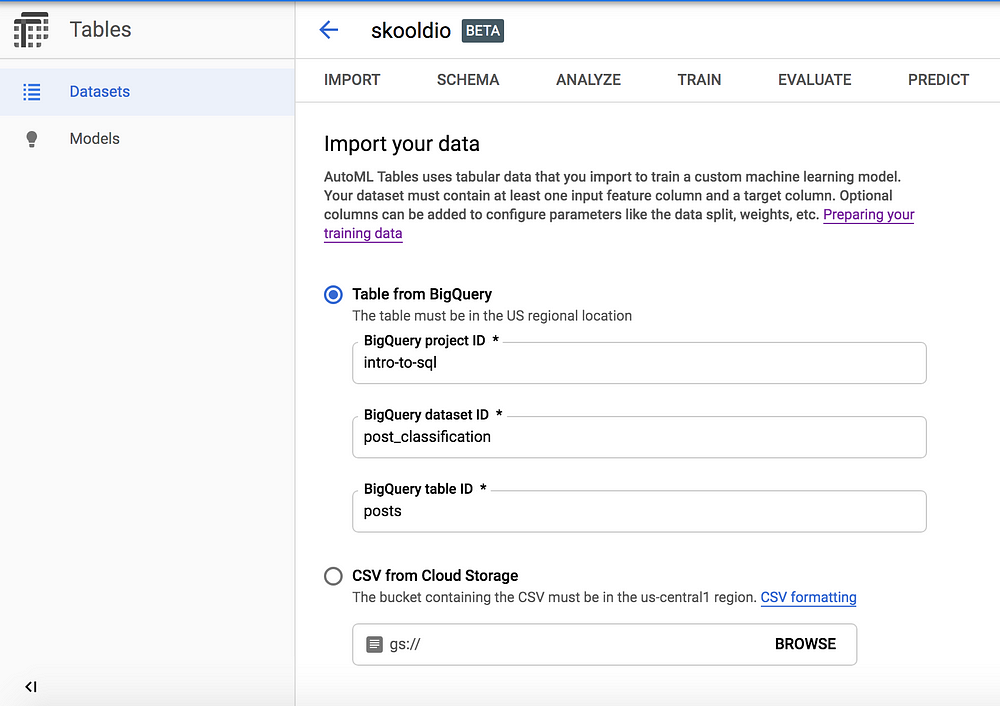
Schema
เมื่อโหลดข้อมูลเรียบร้อย ก็จะมี UI ให้เราระบุประเภทของตัวแปร และกำหนดคอลัมน์ที่เป็น target ที่เราต้องการจะทำนาย ในที่นี่เราต้องการจะทำนายว่าแต่ละโพสต์มาจากเพจไหน จึงตั้ง page ให้เป็น target
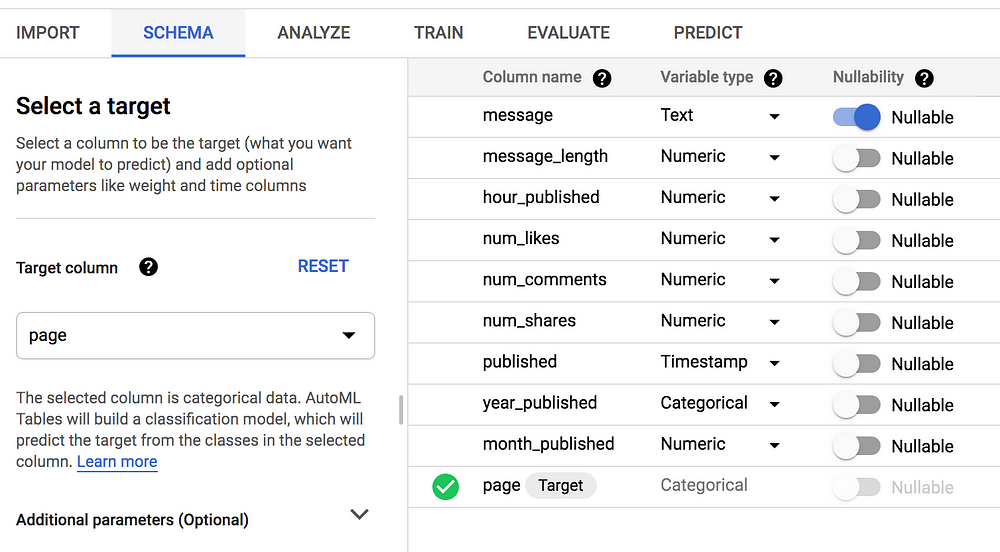
นอกจากนี้ เรายังสามารถระบุรายละเอียดเพิ่มเติมได้ เช่น หากต้องการแบ่งข้อมูล Train / Validate / Test ในสัดส่วนที่ต้องการ ก็ทำได้โดยการสร้างคอลัมน์ที่มีการระบุค่า TRAIN , VALIDATE, TEST เพิ่มขึ้นมา หรือหากต้องการกำหนด weight ให้กับข้อมูลแต่ละตัวไม่เท่ากัน ก็สามารถสร้างคอลัมน์ที่ระบุตัวเลข 0 ถึง 10,000 โดยค่ายิ่งมาก โมเดลก็จะยิ่งให้ความสำคัญมาก และถ้าแถวไหนมีค่าเป็น 0 ก็จะไม่ถูกนำมาใช้
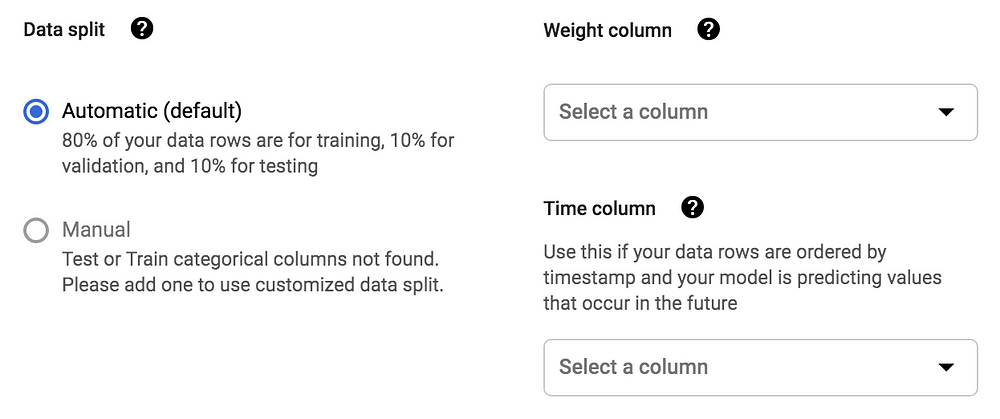
อ่านรายละเอียดเกี่ยวกับการเตรียม dataset เพิ่มเติมได้ที่นี่: https://cloud.google.com/automl-tables/docs/prepare
Analyze
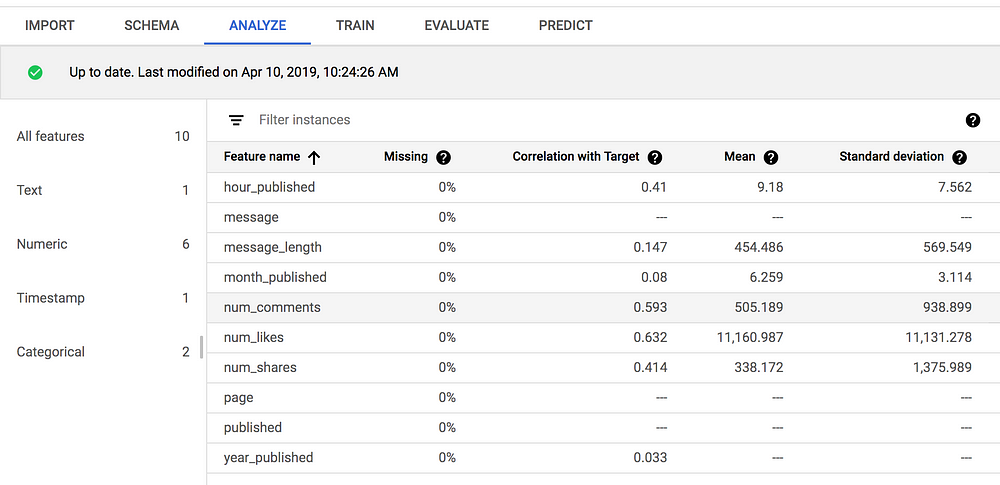
เมื่อกำหนด Schema เสร็จเรียบร้อยแล้ว ก็สามารถมาดูผลวิเคราะห์เร็วๆ ได้ ว่าแต่ละตัวแปร correlate กับ target มากน้อยแค่ไหน มีค่าเฉลี่ย ค่าเบี่ยงเบนมาตรฐานเท่าไหร่ เมื่อเข้าใจข้อมูลและแน่ใจว่าไม่ได้ทำอะไรผิดพลาดแล้ว ก็ไปสร้างโมเดลกันเลย!
Train
ในการ train โมเดล เราจะต้องทำการระบุ budget ที่จะใช้ในการเทรนเป็นชั่วโมง โดยค่าใช้จ่ายตกอยู่ที่ชั่วโมงละ $19.32 😱 (แต่มีให้ลองโดนป้ายยาฟรีๆ ก่อน 6 ชั่วโมง 😂) นอกจากนี้เราสามารถเลือกคอลัมน์ที่จะเอาไปใช้ในการสร้างโมเดลได้อีกด้วย เผื่อไม่อยากใช้คอลัมน์ไหน
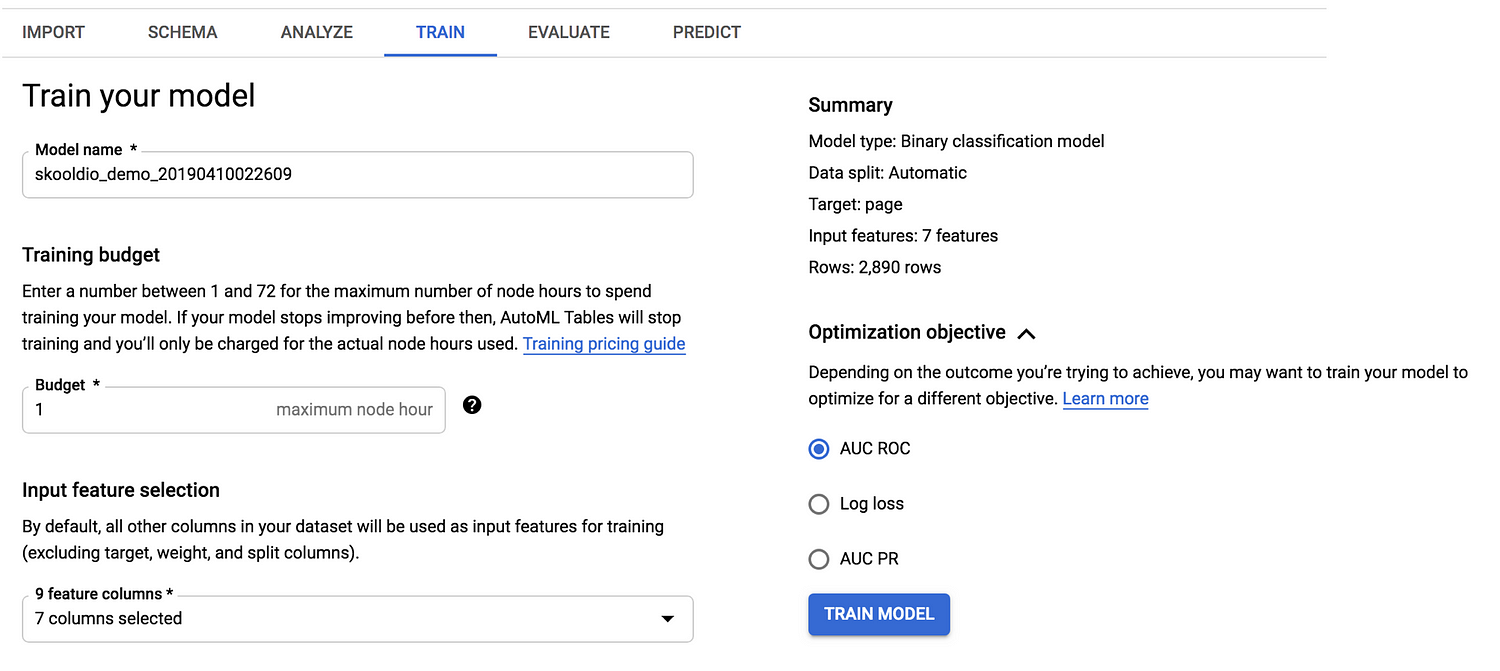
สำหรับโมเดลประเภท Classification เราสามารถเลือก Objective ได้ 3 แบบ ขึ้นอยู่กับว่าเราให้ความสำคัญกับอะไร ขอไม่ลงรายละเอียดเหมือนเดิม เดี๋ยวจะยาว ใครที่สนใจสามารถอ่านเพิ่มเติมได้ที่: https://cloud.google.com/automl-tables/docs/models
เสร็จเรียบร้อยดีแล้วก็กด Train Model เล้ย!!
หลังจากที่รอไปครบ 1 ชั่วโมง ก็ได้ผลลัพธ์หน้าตาประมาณนี้ ระบุรายละเอียด performance ของโมเดลชัดเจนดี
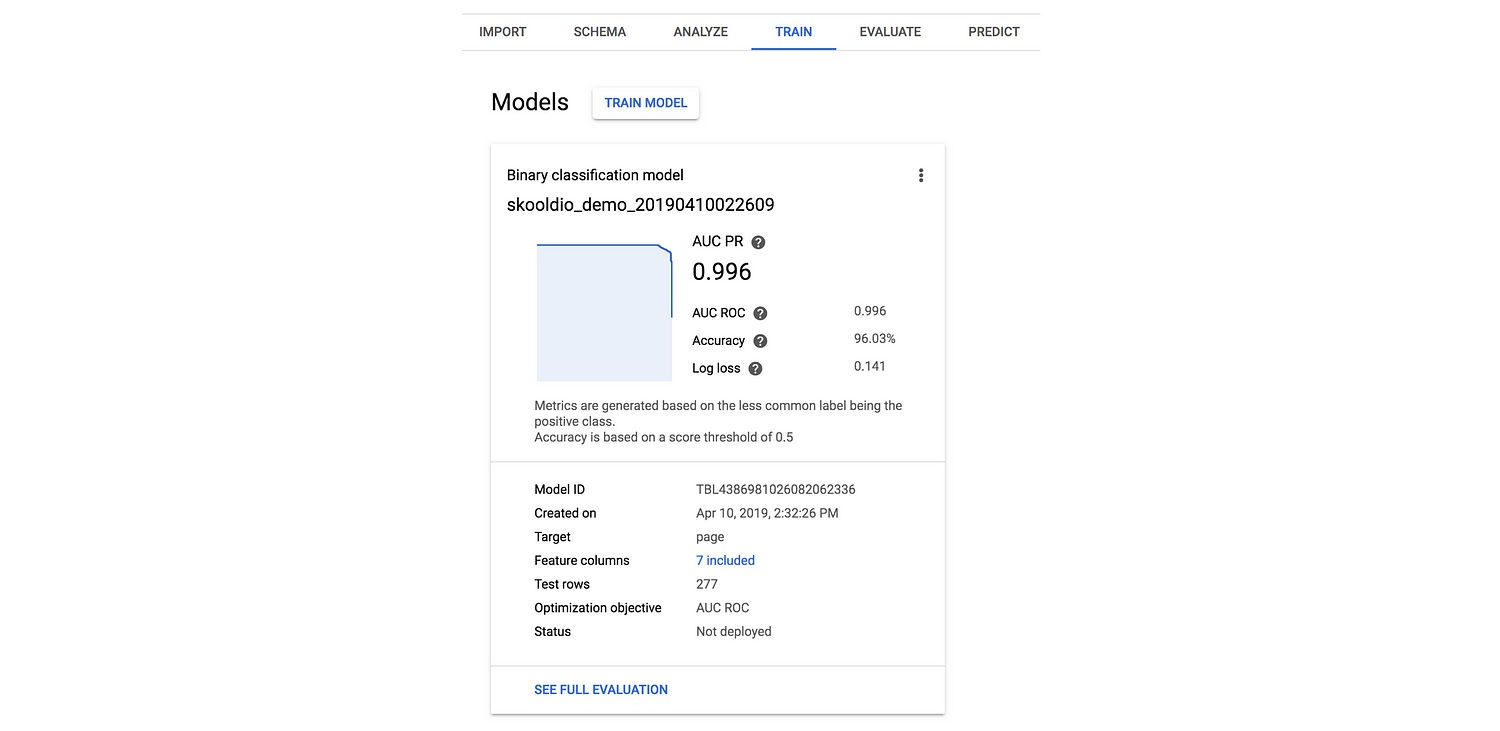
Evaluate
ถ้าผลข้างต้นยังละเอียดไม่พอ เราสามารถมาดูรายละเอียดเพิ่มเติมในส่วนของ Evaluate ได้

ใครที่อยากลองปรับ Threshold ในการตัดสินใจว่าจะเป็น positive หรือ negative ก็สามารถทำได้ง่ายๆ ผ่าน UI ได้เลย
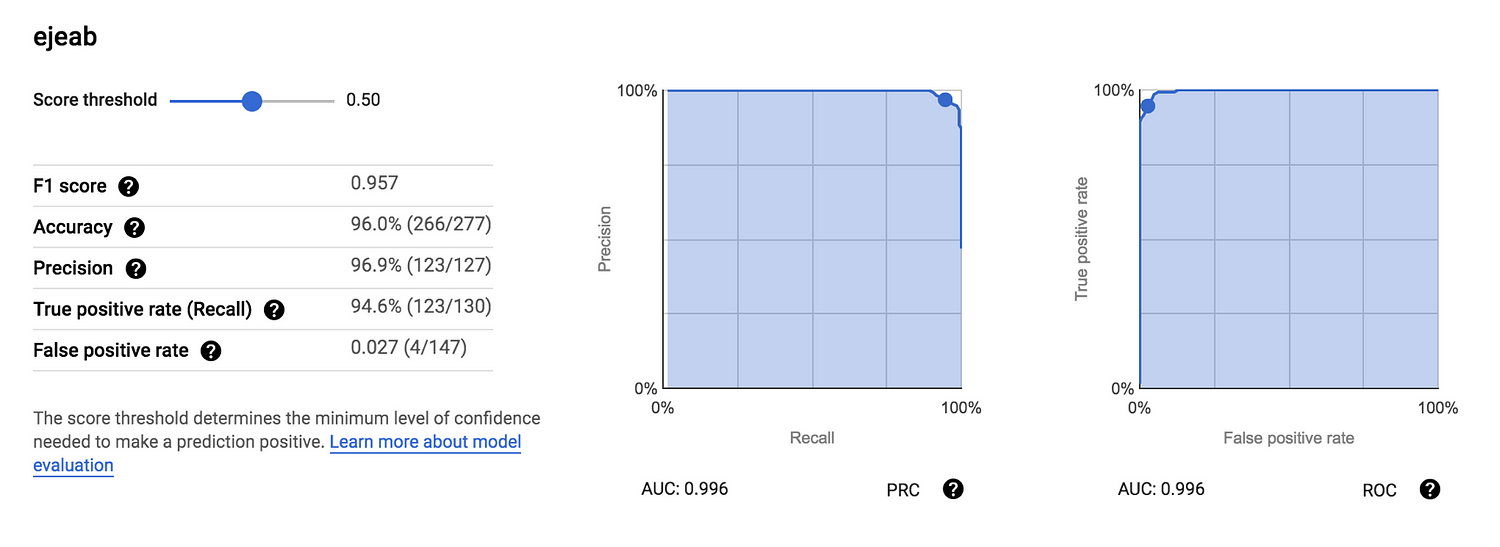
โดยส่วนตัว ประทับใจกับการรายงานผลมากๆ ทำได้ละเอียดและสวยงาม ซึ่งหลายๆ ครั้ง Data Scientist ก็มักจะขี้เกียจ ดูแค่ Accuracy แล้วก็จบกัน อันนี้บังคับดูให้หมดเลย 😂
นอกจากนี้ยังมี Confusion matrix เพื่อแจกแจงว่าที่เดาผิดเดาถูก ผิดเพราะอะไร และยังมี Feature Importance ที่แสดงว่าแต่ละ feature มีส่วนช่วยในการทำนายมากน้อยยังไง
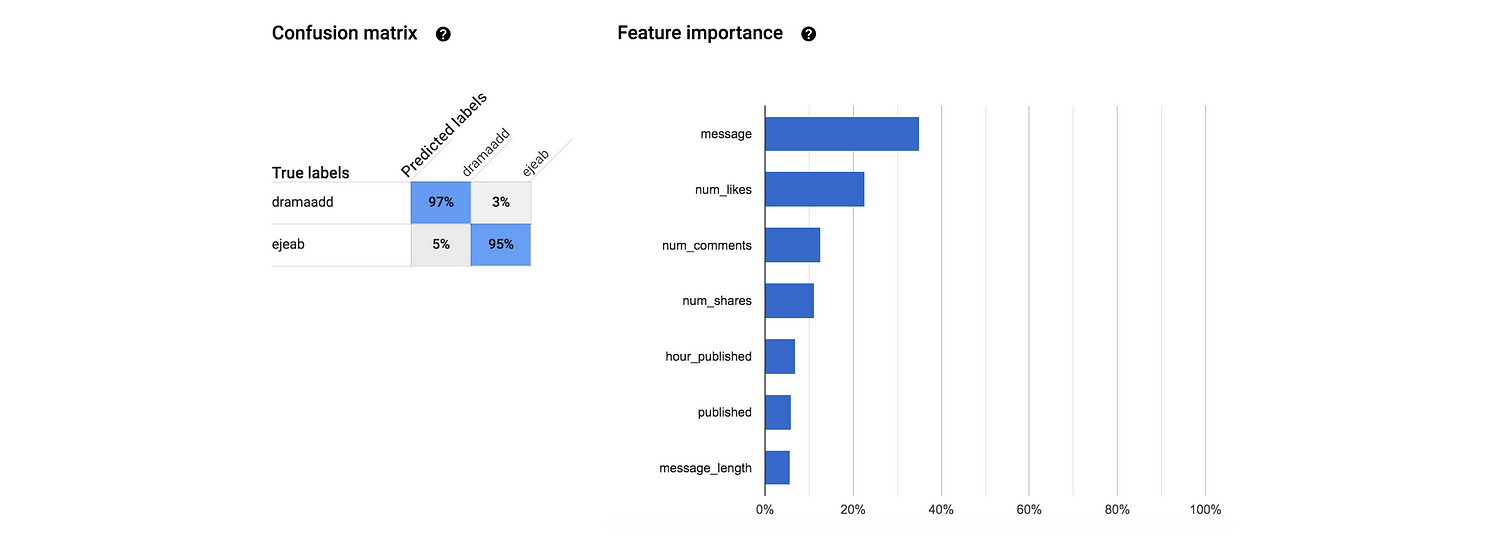
ความเจ๋งอย่างหนึ่งของ AutoML คือ มันประมวลผล Text เอาไปใช้งานในโมเดลให้อัตโนมัติ! อย่างในกรณีนี้เราอยากจะแยกแยะโพสต์จากเพจอีเจี๊ยบกะจ่า ข้อมูลนึงที่น่าจะช่วยเราได้มากๆ ก็คือสำนวนการใช้ภาษาในแต่ละโพสต์ เช่น ถ้ามีคำว่า “หัวล้าน” หลายๆ คนก็น่าจะพอเดาได้แล้วว่าโพสต์นี้มาจากเพจอีเจี๊ยบ
ข้อควรระวังก็คือ การนำ Text ไปใช้ ระบบจะทำการ Tokenize หรือตัดคำด้วยเว้นวรรค ซึ่งถ้าเป็นภาษาอังกฤษ ที่มีการเว้นวรรคระหว่างคำ ก็คือจบเลย พร้อมใช้งาน แต่ถ้าเป็นภาษาไทย และอยากให้ทำงานได้ดี ก็อาจจะต้องไปผ่านกระบวนการตัดคำกันมาก่อน แต่อย่างไรก็ตาม จากผลข้างต้นที่เราได้ ถึงแม้จะไม่มีการตัดคำมาก่อน ผลก็ยังพอได้อยู่ น่าจะเป็นเพราะว่ามีคำเด็ดๆ ที่ใช้แยกแยะทั้งสองเพจได้ ที่มักจะถูกเขียนอยู่โดดๆ (คือมีเว้นวรรคนำหน้าและตามหลัง)
Predict
สุดท้าย ถ้าคิดว่าโมเดลทำงานได้ดีแล้ว การนำไปใช้ สามารถทำได้ 2 แบบด้วยกัน จะทำ Batch Prediction คือ โหลดข้อมูลเข้ามาทำนายเป็นชุดๆ จากไฟล์หรือจาก BigQuery หรือจะทำ Online Prediction คือ เปิดเป็นบริการ ไว้รอทำนายข้อมูลที่ถูกส่งเข้ามา
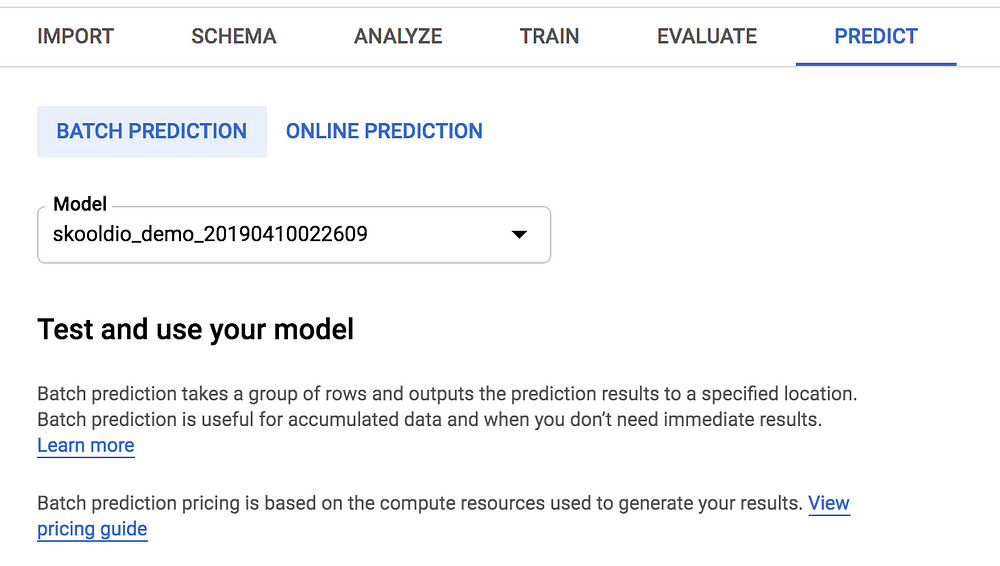
สำหรับ Online Prediction นั้น เราจะต้องทำการ Deploy โมเดลก่อน จึงจะเริ่มใช้งานได้

Disclaimer: โดยส่วนตัวคิดว่าเทคโนโลยีที่เล่ามาทั้งหมดมันเจ๋งมาก และจะช่วยให้หลายๆ องค์กรเริ่มใช้ประโยชน์จากข้อมูลได้มากขึ้นอย่างแน่นอน แต่เครื่องมือแนว “Automagic” นี้ มักจะเป็นดาบสองคม หากผู้ใช้งานไม่มีความรู้พื้นฐานด้าน Machine Learning ที่แข็งแรงพอ แล้วเตรียมข้อมูลมาไม่ดี หรือนำไปใช้ไม่เหมาะสม สุดท้ายอาจจะส่งผลเสียมากกว่าผลดีต่อองค์กรได้


![[Blog Cover] TSS x Skooldio](https://cms-assets.skooldio.com/blog/wp-content/uploads/2025/09/13001445/Blog-Cover-TSS-x-Skooldio-1-400x400.jpg)







